
Using e-ticketing data in transport planning
- Like
- Digg
- Del
- Tumblr
- VKontakte
- Buffer
- Love This
- Odnoklassniki
- Meneame
- Blogger
- Amazon
- Yahoo Mail
- Gmail
- AOL
- Newsvine
- HackerNews
- Evernote
- MySpace
- Mail.ru
- Viadeo
- Line
- Comments
- Yummly
- SMS
- Viber
- Telegram
- Subscribe
- Skype
- Facebook Messenger
- Kakao
- LiveJournal
- Yammer
- Edgar
- Fintel
- Mix
- Instapaper
- Copy Link
Posted: 19 August 2016 | Peter Mott, Solution Director Public Transport, PTV Group | No comments yet
For Intelligent Transport Peter Mott, Solution Director Public Transport at PTV Group, explains how data from electronic fare collection systems can be imported offline into a planning system for further processing and focuses on the example of the SmarTrip® Card in Washington DC.

Objective
Electronic fare collection systems are becoming increasingly popular, especially in the international context. Both the possibility of more flexible and reasonable fares and support with planning make electronic fare collection very attractive. These tickets and fares can be considered reasonable as the rate is calculated on the basis of the route actually travelled and they are more flexible because it is easy to define fares based on the time of day and travel demand.
There are basically two scenarios that need to be taken into consideration when analysing the resulting data for planning purposes:
- Check-in (Ci) only
- Check-in, Check-out (CiCo) or Be-in, Be-out (BiBo) or Check-in, Be-out (CiBo).
Check-in systems with a standard fare are used, for example, in Turkey, the USA and Asia, whereas many metro systems in Europe, the Americas and Asia opt for Check-in, Check-out systems with differentiated fare levels.
Procedure
Data
With simple Ci data on the spatial and temporal distribution of boarding and (where appropriate) transferring passengers is generated, depending on whether the electronic ticket is presented on entering the station or boarding the vehicle.
In the case of CiCo data at the start and end of a journey accumulates from the origin to the destination or even for each path leg, depending on whether the ticket is presented on entering or leaving the station or boarding and alighting the vehicle. Through the vehicle reference, all journey sections and interim transfers, including dwell times, will be recorded individually.
For BiBo ticket data is created in the vehicle at all sections of each line on the leg of the journey from stop-to-stop so that the same information is ultimately available as for vehicle-based CiCo.
For CiCo the data records usually include the following information: Identification of the ticket; date and time of the Ci and Co; and place (station or stop) of the Ci and Co.
BiBo and CiBo data can be compared with the vehicle-based, i.e. line and stop-based case of the CiCo data. BiBo systems therefore provide detailed information when it comes to analysing complex systems, including numerous connection options and a large number of passengers transferring at central stations.
Various data formats are created depending on the method used for collecting electronic ticket data:
- A single record per journey for the station-based CiCo, for example, in metro systems
- A single record per path-leg for vehicle-based collection, i.e. for full CiCo or BiBo.
In practice, a transport area often uses hybrid forms of different methods.
Processing route information
The boarding and alighting passenger operations created with CiCo allow refined analyses. However, this method involves additional pre-processing steps.
If all of a passenger’s path-legs are created individually, it must first be determined which path-legs belong to a common OD pair, i.e. to a specific journey with several lines. This can be checked through correlation or spatial linking of the stations and the time between alighting and re-boarding.
If it is not possible to collect data on all path-legs taken by a passenger, data processing needs to be based on assumptions about the passenger’s behaviour – such as for assignments. Possible path-legs can be determined by means of appropriate methods, if the main purpose of the journey is to get from the origin to the destination as quickly as possible. It becomes more difficult if the passenger takes on additional activities at multi-functional stop-over stations. These may include shopping or taking a break for refreshments, which considerably increases the ideal journey time.
The fundamental aim of processing CiCo data is to reconstruct in detail the entire journey between the origin and destination stop, including all path-legs, in order to determine all path lengths, travel and wait times, as well as passenger transfers and fare information, if applicable.
Importing route data into a transport planning system
For many years the PTV Visum transport planning system has offered a module for importing passenger travel data sourced externally1.
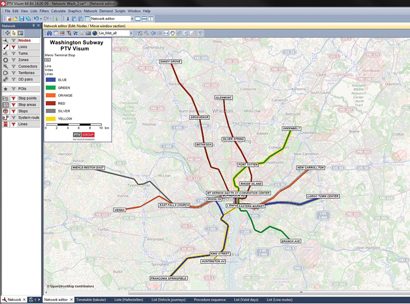
Figure 1: Network of the Washington Subway with lines and terminal stops
Originally, the method for computer-aided plausibility checks of survey data was designed for conventional passenger surveys. Owing to time limitations for interviews, but also because passengers might not be able to provide detailed information on their precise route choice at the time of the interview, only benchmark figures can be obtained. After the survey, the most probable overall path route is reconstructed by comparing it with the line diagram and timetable and allocating the corresponding travel demand to the lines in question.
If the procedure is flexible in terms of parameters and data formats permitted, passenger routes described by CiCo data can be precisely reconstructed.
The external route data is imported in three stages: Import of external data; plausibility check; and the so-called direct assignment. During the import, the data is checked in terms of completeness and formal correctness. After this first step, the boarding and alighting stops and optional transfer stops can be presented graphically.
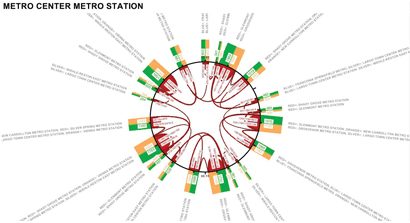
Figure 2: Passenger transfer from one journey to another within one hour at a selected subway station
The plausibility checks are to reconstruct the path travelled by the passenger using the imported information. This includes all characteristics available for each path-leg, such as boarding and alighting stops, time of check-in and – if available – the name of the line and direction. The planner can specify to what extent deviating or incomplete entries may be supplemented by using additional parameters. For example, a difference between the time stamp of the electronic ticket and the time of departure makes sense for stationbased check-ins. For systems with only one check-in and one check-out, it is verified whether transfers are required between origin and destination. Path-legs are then added, where appropriate.
The third step consists of the so-called direct assignment where all plausible path-legs are mapped onto the line routes and timetable enabling all evaluations of a conventional assignment to be carried out.
The experience made with data records of existing e-ticketing systems, shows that this three-step process can be performed for up to one million data records in less than an hour.
Analysis of travel demand using the example of Washington Metro
Overview of the example used
The application described here was initiated through a blog of the Washington Metropolitan Area Transit Authority (WMATA) which was founded in 1967 for the purpose of planning, developing, establishing, financing and operating a balanced regional transport system in the capital’s region2. In early-2015 PlanItMetro, the Metro’s Planning Blog, started an appeal to download the demand data provided and to show how it could be used in planning systems. The travel demand data collected by the SmarTrip®-system was available in the form of aggregated origin-destination matrices and included information on the month, year, type of day, transport times, 15-minute time intervals and the check-in and check-out stations3. Upon request, WMATA later provided PTV with an
additional data sample of approximately 240,000 randomly chosen individual paths with anonymised ticket IDs, station names and check-in and check-out times.
The network required for data analysis and display, as well as the schedule of the Metrorail system, could simply be downloaded from the Internet as a GTFS feed (General Transit Format Specification)4 and imported into the planning system via a standard interface. The Metrorail network used was comprised of 91 stations, including 22 terminal stops, six lines with a total of 34 line routes and 1,640 train trips on an average working day (see Figure 1).
The demand data could be imported in both formats. The trans – action data required only minimal pre-processing prior to being imported from the SmarTrip® system. The analyses presented below were created to improve data completeness with the help of the station-specific matrices aggregated for 15-minute intervals between 6.30am and 8.30am.
Network-wide travel demand
The analyses revealed approximately 138,000 passengers during the morning rush hour observed. A split between direct passengers and transferring passengers shows that the share of direct passengers (with approximately 31%) is significantly smaller than that of passengers transferring once (65%). Only very few passengers (4%) transfer more than once. The high number of transfers suggests that many stations possess an effective infrastructure in order to ensure a smooth flow of passengers.
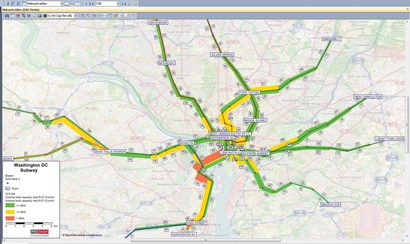
Figure 3: Volume capacity ratio in the morning peak period between
7.30am and 8.00am
An overview of the transfers per stop – from line and direction to line and direction – can be used as a reference for passenger guidance in stations and for dimensioning routes, escalators and elevators. Figure 2 shows the transfers between individual trains for a selected station.
Demand and volume/capacity ratio by links, lines and journey
The demand obtained by retracing the passenger routes can be displayed and analysed by link and route. For a high-performance system that at least occasionally operates at full capacity, in addition to information on the spatial distribution of travel demand, the exact time distribution of demand is of prime importance. It is therefore vital to obtain a time reference through both conventional assignment of temporally highly differentiated origin-destination matrices and check-in/check-out data. In PTV Visum, the demand and the volume/capacity ratio can be calculated and displayed for user-defined analysis intervals of, for example, 15 or 30 minutes5.
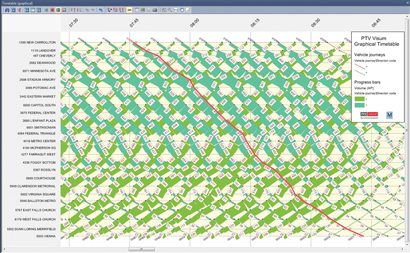
Figure 4: Passenger volume per vehicle journey in the graphical timetable of one line
Analyses of volume/capacity ratios are illustrated particularly well in classified displays. For instance, if calculations are performed for three different cases with volume/capacity ratios of up to 60%, up to 90% and above, and then highlighted in different colours, it becomes clear when and on which routes/lines critical situations are expected (see Figure 3). In a strategic planning system, it can be checked whether larger vehicles or shorter headways could alleviate the situation.
In PTV Visum, the demand can be assigned to each vehicle journey via the timetable-based assignment or the direct assignment. In PTV Visum’s graphical timetable, the time-route diagram (see Figure 4) shows the travel demand or the volume/capacity ratio between the individual stops. This diagram allows planners to quickly recognise which journeys are critical and how many passengers would be affected by changes to transport supply.
Additional use cases
The travel demand per journey (section) may also be used for vehicle scheduling. Modern, efficient procedures allow you to assign a group of interchangeable vehicle types to the vehicle journeys defined in the timetable and then leave it to the optimisation process to select the most cost-efficient alternative.
The strategic planning software PTV Visum also allows you to include the travel demand into these procedures. This means you can compare the travel demand estimated from model-based calculations or available from passenger count or ticketing data with the capacity of the deployable vehicle types. This way, not only the most economical vehicle type can be selected, but also the one that best meets the travel demand.
Summary
Electronic payment systems that provide detailed information on travel demand, or even on OD pairs, have been available for some years now. There are efficient tools that allow you to display this data and use it for planning purposes.
Particularly OD data obtained from a CiCo system offers a wide range of processing options, as each passenger journey can be traced back in detail. By connecting supply and demand, you can provide a variety of highly differentiated spatial and temporal information. Examples thereof include:
- Travel demand listed by stops, routes or lines
- Volume/capacity ratio of vehicles
- Fare revenues listed by links, lines or modes oftransport/operators.
For the optimisation of vehicle deployment, ticketing data can be used to select suitable vehicle types based on their capacity.
Currently, e-ticketing data analyses are mainly performed in Asia, where numerous electronic ticketing systems record several million transactions per day. One objective is to analyse the paths actually used by passengers to determine appropriate parameters for simulating future scenarios.
References
- www.visiontraffic.ptvgroup.com/fileadmin/files_ptvvision/Downloads_N/0_General/2_Products/1_PTV_Visum/Module_PTVVisum_DE.pdf
- www.wmata.com/about_metro
- www.planitmetro.com, demand data is no longer provided there
- www.wmata.com/rider_tools/developer_resources.cfm and also www.gtfs-data-exchange.com/agency/wmata
- In this case, no information on vehicle deployment was available as a GTFS feed. After consultation with WMATA, estimates of carriage dimensions and train compositions had to be made in order to calculate the volume/capacity ratio.
About the author

Dr.-Ing. Peter Mott is Solution Director Public Transport at PTV Group. His professional experience includes public transport consulting, as well as the application of strategic and operational public transport software systems. Peter supports the application of the PTV Vision suite in public transport. Peter also lectures at the Karlsruhe University of Applied Sciences.
Related topics
Fleet Management & Maintenance, Multimodality, Ticketing & Payments, Transport Governance & Policy
Issue
Issue 4 2016



